

Para administrar la complejidad de los problemas y el proceso de solución de problemas, los científicos de la computación usan abstracciones que les permiten enfocarse en el “panorama general” sin perder de vista los detalles. Mediante la creación de modelos del dominio del problema, somos capaces de utilizar un mejor y más eficiente proceso de solución de problemas. Estos modelos nos permiten describir los datos que nuestros algoritmos manipularán en una manera mucho más consistente con respecto al problema en sí mismo.
Nos referimos anteriormente a la abstracción procedimental como un proceso que oculta los detalles de una función particular para permitir que el usuario o el cliente la vea a un muy alto nivel. Ahora dirigimos nuestra atención a una idea similar, aquélla de la abstracción de datos. Un tipo abstracto de datos, algunas veces abreviado TAD, es una descripción lógica de cómo vemos los datos y las operaciones que son permitidas sin importar cómo serán implementadas. Esto significa que estamos preocupados únicamente por lo qué están representando los datos y no por cómo serán construidos eventualmente. Al proporcionar este nivel de abstracción, estamos creando un encapsulamiento alrededor de los datos. La idea es que, al encapsular los detalles de la implementación, los estamos ocultando de la vista del usuario. Esto se denomina ocultamiento de información.
La Figura muestra una imagen de qué es un tipo abstracto de datos y cómo opera. El usuario interactúa con la interfaz, usando las operaciones que han sido especificadas por el tipo abstracto de datos. El tipo abstracto de datos es el cascarón con el que el usuario interactúa. La implementación está oculta un nivel más en profundidad. El usuario no se preocupa de los detalles de la implementación.
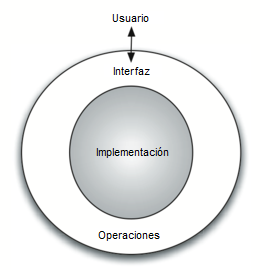
La implementación de un tipo abstracto de datos, a menudo denominada estructura de datos, requerirá que proporcionemos una vista física de los datos usando alguna colección de estructuras de programación y tipos de datos primitivos. Como hemos discutido anteriormente, la separación de estas dos perspectivas nos permitirá definir los modelos de datos complejos para nuestros problemas sin dar ninguna indicación sobre los detalles de cómo se construirá realmente el modelo. Esto proporciona una vista de los datos independiente de la implementación. Dado que normalmente habrá muchas maneras diferentes de implementar un tipo abstracto de datos, esta independencia de la implementación permite al programador modificar los detalles de la implementación sin cambiar la forma en la que el usuario de los datos interactúa con ella. El usuario puede así mantenerse enfocado en el proceso de solución de problemas.













{kind=link}